Tutorial: Navigation in MiniGrid.#
In this tutorial, we will train an agent to complete the MiniGrid-Empty-Random-5x5-v0 task within the
MiniGrid environment. We will demonstrate how to:
- Write an experiment configuration file with a simple training pipeline from scratch.
- Use one of the supported environments with minimal user effort.
- Train, validate and test your experiment from the command line.
This tutorial assumes the installation instructions have already been
followed and that, to some extent, this framework's abstractions are known.
The extra_requirements for minigrid_plugin and babyai_plugin can be installed with.
pip install -r allenact_plugins/minigrid_plugin/extra_requirements.txt; pip install -r allenact_plugins/babyai_plugin/extra_requirements.txt
The task#
A MiniGrid-Empty-Random-5x5-v0 task consists of a grid of dimensions 5x5 where an agent spawned at a random
location and orientation has to navigate to the visitable bottom right corner cell of the grid by sequences of three
possible actions (rotate left/right and move forward). A visualization of the environment with expert steps in a random
MiniGrid-Empty-Random-5x5-v0 task looks like

The observation for the agent is a subset of the entire grid, simulating a simplified limited field of view, as depicted by the highlighted rectangle (observed subset of the grid) around the agent (red arrow). Gray cells correspond to walls.
Experiment configuration file#
Our complete experiment consists of:
- Training a basic actor-critic agent with memory to solve randomly sampled navigation tasks.
- Validation on a fixed set of tasks (running in parallel with training).
- A second stage where we test saved checkpoints with a larger fixed set of tasks.
The entire configuration for the experiment, including training, validation, and testing, is encapsulated in a single
class implementing the ExperimentConfig abstraction. For this tutorial, we will follow the config under
projects/tutorials/minigrid_tutorial.py.
The ExperimentConfig abstraction is used by the
OnPolicyTrainer class (for training) and the
OnPolicyInference class (for validation and testing)
invoked through the entry script main.py that calls an orchestrating
OnPolicyRunner class. It includes:
- A
tagmethod to identify the experiment. - A
create_modelmethod to instantiate actor-critic models. - A
make_sampler_fnmethod to instantiate task samplers. - Three
{train,valid,test}_task_sampler_argsmethods describing initialization parameters for task samplers used in training, validation, and testing; including assignment of workers to devices for simulation. - A
machine_paramsmethod with configuration parameters that will be used for training, validation, and testing. - A
training_pipelinemethod describing a possibly multi-staged training pipeline with different types of losses, an optimizer, and other parameters like learning rates, batch sizes, etc.
Preliminaries#
We first import everything we'll need to define our experiment.
from typing import Dict, Optional, List, Any, cast
import gym
from gym_minigrid.envs import EmptyRandomEnv5x5
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import LambdaLR
from allenact.algorithms.onpolicy_sync.losses.ppo import PPO, PPOConfig
from allenact.base_abstractions.experiment_config import ExperimentConfig, TaskSampler
from allenact.base_abstractions.sensor import SensorSuite
from allenact.utils.experiment_utils import (
TrainingPipeline,
Builder,
PipelineStage,
LinearDecay,
)
from allenact_plugins.minigrid_plugin.minigrid_models import MiniGridSimpleConvRNN
from allenact_plugins.minigrid_plugin.minigrid_sensors import EgocentricMiniGridSensor
from allenact_plugins.minigrid_plugin.minigrid_tasks import (
MiniGridTaskSampler,
MiniGridTask,
)
We now create the MiniGridTutorialExperimentConfig class which we will use to define our experiment.
For pedagogical reasons, we will add methods to this class one at a time below with a description of what
these classes do.
class MiniGridTutorialExperimentConfig(ExperimentConfig):
An experiment is identified by a tag.
@classmethod
def tag(cls) -> str:
return "MiniGridTutorial"
Sensors and Model#
A readily available Sensor type for MiniGrid,
EgocentricMiniGridSensor,
allows us to extract observations in a format consumable by an ActorCriticModel agent:
SENSORS = [
EgocentricMiniGridSensor(agent_view_size=5, view_channels=3),
]
The three view_channels include objects, colors and states corresponding to a partial observation of the environment
as an image tensor, equivalent to that from ImgObsWrapper in
MiniGrid. The
relatively large agent_view_size means the view will only be clipped by the environment walls in the forward and
lateral directions with respect to the agent's orientation.
We define our ActorCriticModel agent using a lightweight implementation with recurrent memory for MiniGrid
environments, MiniGridSimpleConvRNN:
@classmethod
def create_model(cls, **kwargs) -> nn.Module:
return MiniGridSimpleConvRNN(
action_space=gym.spaces.Discrete(len(MiniGridTask.class_action_names())),
observation_space=SensorSuite(cls.SENSORS).observation_spaces,
num_objects=cls.SENSORS[0].num_objects,
num_colors=cls.SENSORS[0].num_colors,
num_states=cls.SENSORS[0].num_states,
)
Task samplers#
We use an available TaskSampler implementation for MiniGrid environments that allows to sample both random and
deterministic MiniGridTasks,
MiniGridTaskSampler:
@classmethod
def make_sampler_fn(cls, **kwargs) -> TaskSampler:
return MiniGridTaskSampler(**kwargs)
This task sampler will during training (or validation/testing), randomly initialize new tasks for the agent to complete.
While it is not quite as important for this task type (as we test our agent in the same setting it is trained on) there
are a lot of good reasons we would like to sample tasks differently during training than during validation or testing.
One good reason, that is applicable in this tutorial, is that, during training, we would like to be able to sample tasks
forever while, during testing, we would like to sample a fixed number of tasks (as otherwise we would never finish
testing!). In allenact this is made possible by defining different arguments for the task sampler:
def train_task_sampler_args(
self,
process_ind: int,
total_processes: int,
devices: Optional[List[int]] = None,
seeds: Optional[List[int]] = None,
deterministic_cudnn: bool = False,
) -> Dict[str, Any]:
return self._get_sampler_args(process_ind=process_ind, mode="train")
def valid_task_sampler_args(
self,
process_ind: int,
total_processes: int,
devices: Optional[List[int]] = None,
seeds: Optional[List[int]] = None,
deterministic_cudnn: bool = False,
) -> Dict[str, Any]:
return self._get_sampler_args(process_ind=process_ind, mode="valid")
def test_task_sampler_args(
self,
process_ind: int,
total_processes: int,
devices: Optional[List[int]] = None,
seeds: Optional[List[int]] = None,
deterministic_cudnn: bool = False,
) -> Dict[str, Any]:
return self._get_sampler_args(process_ind=process_ind, mode="test")
where, for convenience, we have defined a _get_sampler_args method:
def _get_sampler_args(self, process_ind: int, mode: str) -> Dict[str, Any]:
"""Generate initialization arguments for train, valid, and test
TaskSamplers.
# Parameters
process_ind : index of the current task sampler
mode: one of `train`, `valid`, or `test`
"""
if mode == "train":
max_tasks = None # infinite training tasks
task_seeds_list = None # no predefined random seeds for training
deterministic_sampling = False # randomly sample tasks in training
else:
max_tasks = 20 + 20 * (mode == "test") # 20 tasks for valid, 40 for test
# one seed for each task to sample:
# - ensures different seeds for each sampler, and
# - ensures a deterministic set of sampled tasks.
task_seeds_list = list(
range(process_ind * max_tasks, (process_ind + 1) * max_tasks)
)
deterministic_sampling = (
True # deterministically sample task in validation/testing
)
return dict(
max_tasks=max_tasks, # see above
env_class=self.make_env, # builder for third-party environment (defined below)
sensors=self.SENSORS, # sensors used to return observations to the agent
env_info=dict(), # parameters for environment builder (none for now)
task_seeds_list=task_seeds_list, # see above
deterministic_sampling=deterministic_sampling, # see above
)
@staticmethod
def make_env(*args, **kwargs):
return EmptyRandomEnv5x5()
Note that the env_class argument to the Task Sampler is the one determining which task type we are going to train the
model for (in this case, MiniGrid-Empty-Random-5x5-v0 from
gym-minigrid)
. The sparse reward is
given by the environment
, and the maximum task length is 100. For training, we opt for a default random sampling, whereas for validation and
test we define fixed sets of randomly sampled tasks without needing to explicitly define a dataset.
In this toy example, the maximum number of different tasks is 32. For validation we sample 320 tasks using 16 samplers, or 640 for testing, so we can be fairly sure that all possible tasks are visited at least once during evaluation.
Machine parameters#
Given the simplicity of the task and model, we can quickly train the model on the CPU:
@classmethod
def machine_params(cls, mode="train", **kwargs) -> Dict[str, Any]:
return {
"nprocesses": 128 if mode == "train" else 16,
"devices": [],
}
We allocate a larger number of samplers for training (128) than for validation or testing (16), and we default to CPU
usage by returning an empty list of devices.
Training pipeline#
The last definition required before starting to train is a training pipeline. In this case, we just use a single PPO stage with linearly decaying learning rate:
@classmethod
def training_pipeline(cls, **kwargs) -> TrainingPipeline:
ppo_steps = int(150000)
return TrainingPipeline(
named_losses=dict(ppo_loss=PPO(**PPOConfig)), # type:ignore
pipeline_stages=[
PipelineStage(loss_names=["ppo_loss"], max_stage_steps=ppo_steps)
],
optimizer_builder=Builder(cast(optim.Optimizer, optim.Adam), dict(lr=1e-4)),
num_mini_batch=4,
update_repeats=3,
max_grad_norm=0.5,
num_steps=16,
gamma=0.99,
use_gae=True,
gae_lambda=0.95,
advance_scene_rollout_period=None,
save_interval=10000,
metric_accumulate_interval=1,
lr_scheduler_builder=Builder(
LambdaLR, {"lr_lambda": LinearDecay(steps=ppo_steps)} # type:ignore
),
)
You can see that we use a Builder class to postpone the construction of some of the elements, like the optimizer,
for which the model weights need to be known.
Training and validation#
We have a complete implementation of this experiment's configuration class in projects/tutorials/minigrid_tutorial.py.
To start training from scratch, we just need to invoke
PYTHONPATH=. python allenact/main.py minigrid_tutorial -b projects/tutorials -m 8 -o /PATH/TO/minigrid_output -s 12345
from the allenact root directory.
- With
-b projects/tutorialswe tellallenactthatminigrid_tutorialexperiment config file will be found in theprojects/tutorialsdirectory. - With
-m 8we limit the number of subprocesses to 8 (each subprocess will run 16 of the 128 training task samplers). - With
-o minigrid_outputwe set the output folder into which results and logs will be saved. - With
-s 12345we set the random seed.
If we have Tensorboard installed, we can track progress with
tensorboard --logdir /PATH/TO/minigrid_output
which will default to the URL http://localhost:6006/.
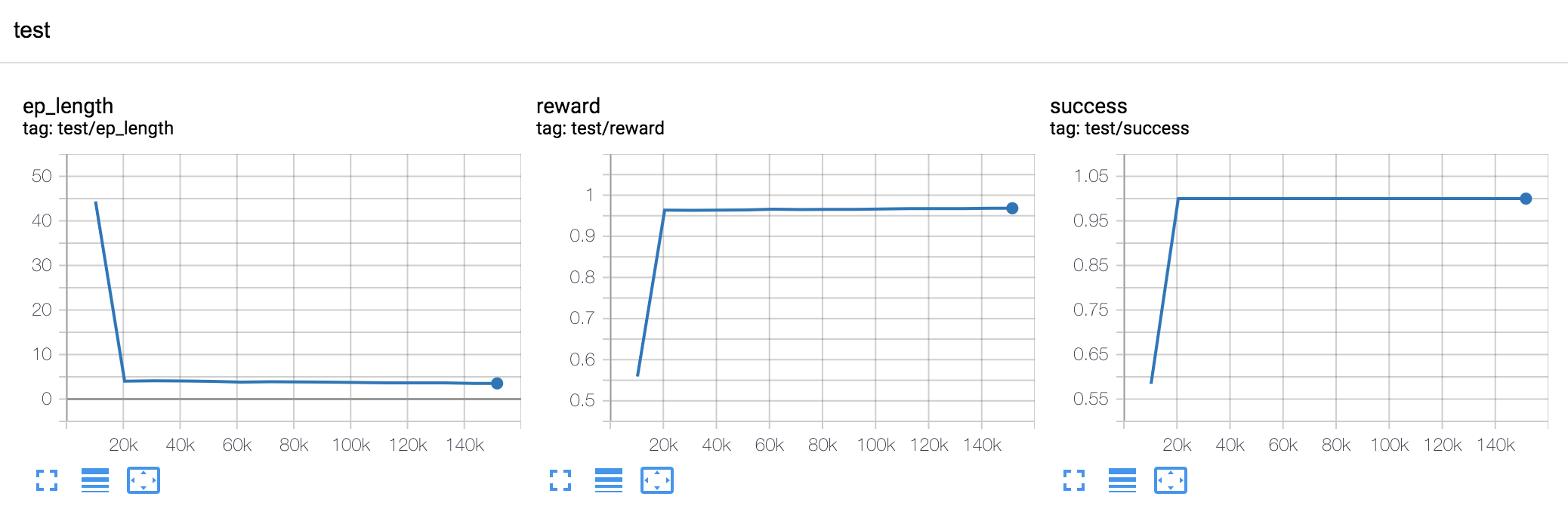
After 150,000 steps, the script will terminate and several checkpoints will be saved in the output folder. The training curves should look similar to:
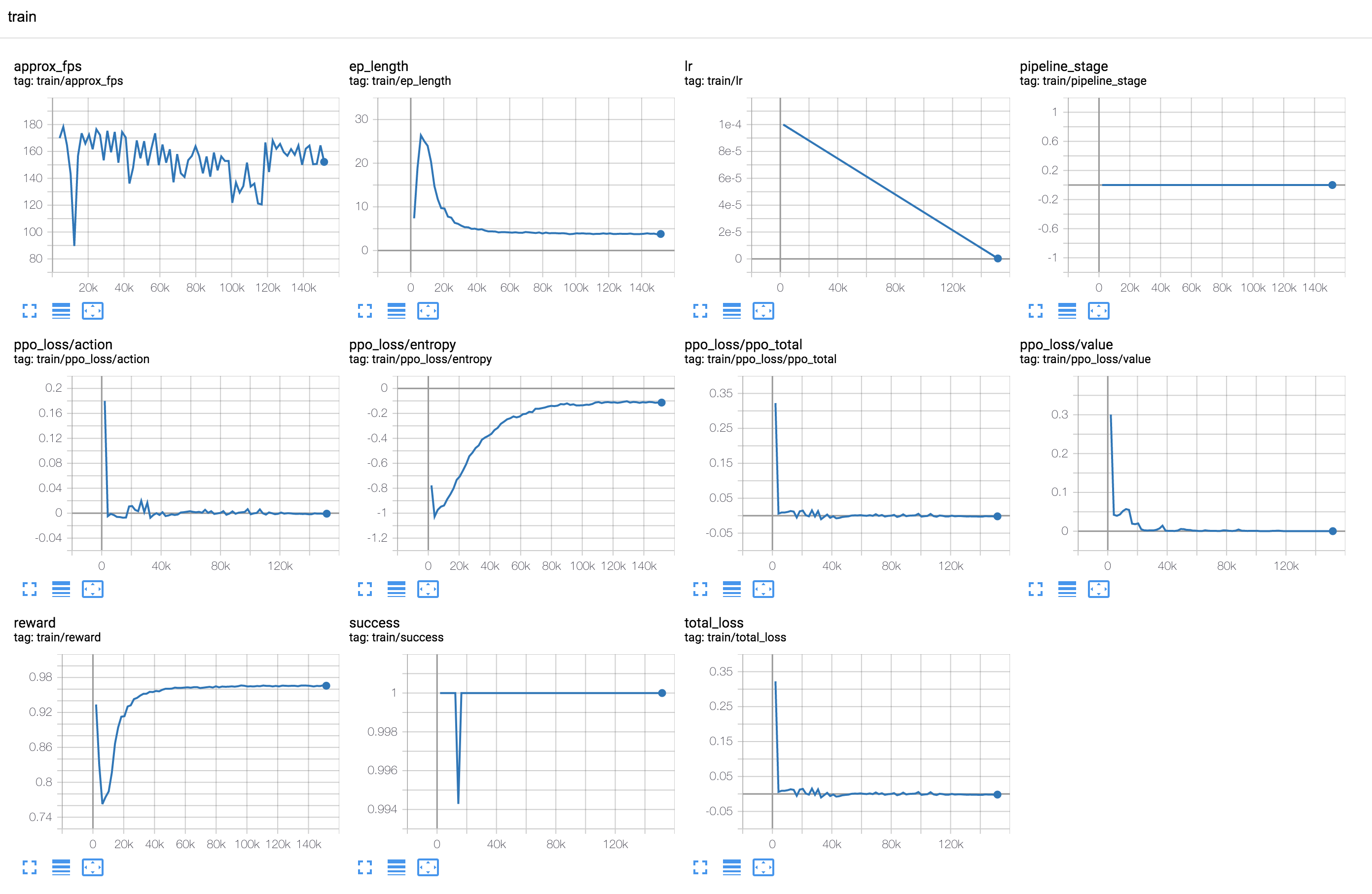
If everything went well, the valid success rate should converge to 1 and the mean episode length to a value below 4.
(For perfectly uniform sampling and complete observation, the expectation for the optimal policy is 3.75 steps.) In the
not-so-unlikely event of the run failing to converge to a near-optimal policy, we can just try to re-run (for example
with a different random seed). The validation curves should look similar to:
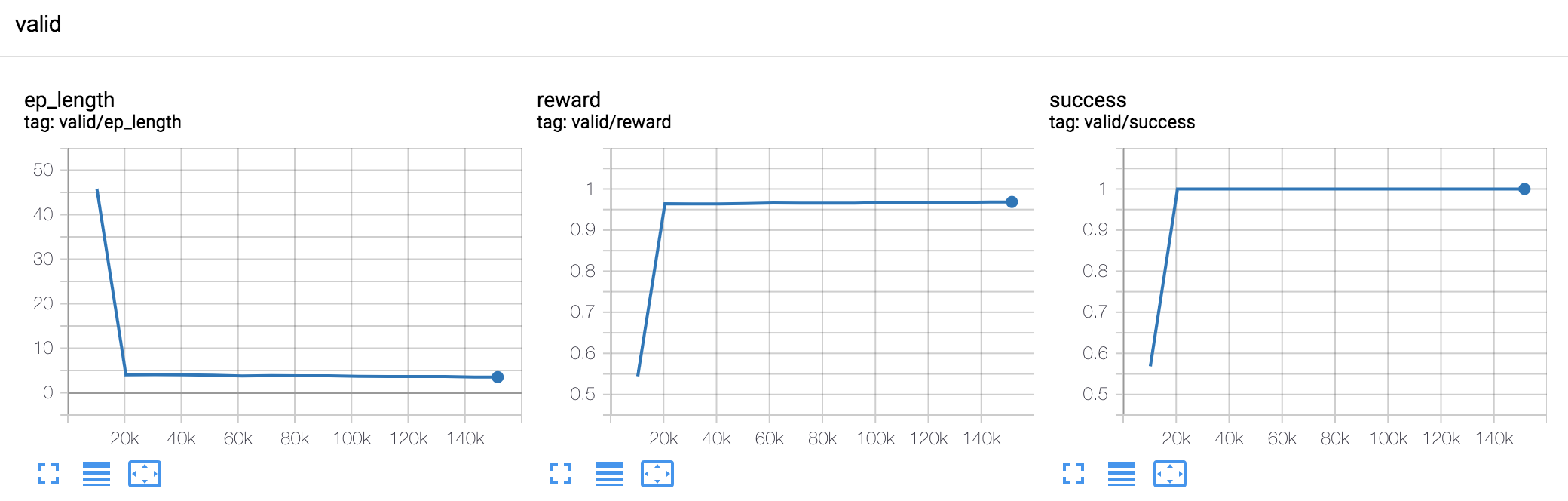
Testing#
The training start date for the experiment, in YYYY-MM-DD_HH-MM-SS format, is used as the name of one of the
subfolders in the path to the checkpoints, saved under the output folder.
In order to evaluate (i.e. test) a particular checkpoint, we need to pass the --eval flag and specify the checkpoint with the
--checkpoint CHECKPOINT_PATH option:
PYTHONPATH=. python allenact/main.py minigrid_tutorial \
-b projects/tutorials \
-m 1 \
-o /PATH/TO/minigrid_output \
-s 12345 \
--eval \
--checkpoint /PATH/TO/minigrid_output/checkpoints/MiniGridTutorial/YOUR_START_DATE/exp_MiniGridTutorial__stage_00__steps_000000151552.pt
Again, if everything went well, the test success rate should converge to 1 and the mean episode length to a value
below 4. Detailed results are saved under a metrics subfolder in the output folder.
The test curves should look similar to: