Tutorial: OpenAI gym for continuous control.#
Note The provided commands to execute in this tutorial assume you have
installed the full library and the requirements for the
gym_plugin. The latter can be installed by
pip install -r allenact_plugins/gym_plugin/extra_requirements.txt
In this tutorial, we:
- Introduce the
gym_plugin, which enables some of the tasks in OpenAI's gym for training and inference within AllenAct. - Show an example of continuous control with an arbitrary action space covering 2 policies for one of the
gymtasks.
The task#
For this tutorial, we'll focus on one of the continuous-control environments under the Box2D group of gym
environments: LunarLanderContinuous-v2. In this task, the goal
is to smoothly land a lunar module in a landing pad, as shown below.
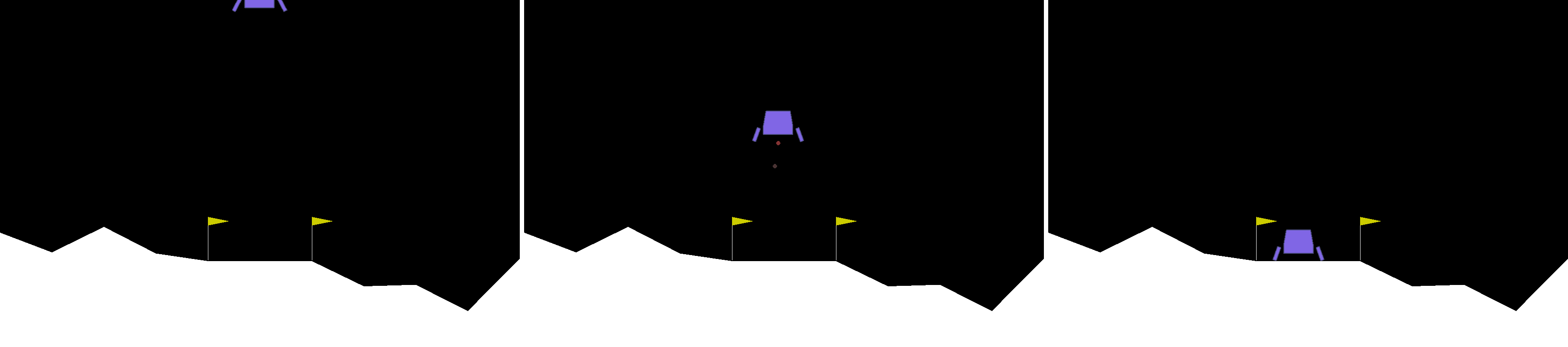 .
.
To achieve this goal, we need to provide continuous control for a main engine and directional one (2 real values). In
order to solve the task, the expected reward is of at least 200 points. The controls for main and directional engines
are both in the range [-1.0, 1.0] and the observation space is composed of 8 scalars indicating x and y positions,
x and y velocities, lander angle and angular velocity, and left and right ground contact. Note that these 8 scalars
provide a full observation of the state.
Implementation#
For this tutorial, we'll use the readily available gym_plugin, which includes a
wrapper for gym environments, a
task sampler and
task definition, a
sensor to wrap the observations provided by the gym
environment, and a simple model.
The experiment config, similar to the one used for the Navigation in MiniGrid tutorial, is defined as follows:
from typing import Dict, Optional, List, Any, cast
import gym
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import LambdaLR
from allenact.algorithms.onpolicy_sync.losses.ppo import PPO
from allenact.base_abstractions.experiment_config import ExperimentConfig, TaskSampler
from allenact.base_abstractions.sensor import SensorSuite
from allenact_plugins.gym_plugin.gym_models import MemorylessActorCritic
from allenact_plugins.gym_plugin.gym_sensors import GymBox2DSensor
from allenact_plugins.gym_plugin.gym_tasks import GymTaskSampler
from allenact.utils.experiment_utils import (
TrainingPipeline,
Builder,
PipelineStage,
LinearDecay,
)
from allenact.utils.viz_utils import VizSuite, AgentViewViz
class GymTutorialExperimentConfig(ExperimentConfig):
@classmethod
def tag(cls) -> str:
return "GymTutorial"
Sensors and Model#
As mentioned above, we'll use a GymBox2DSensor to provide
full observations from the state of the gym environment to our model.
SENSORS = [
GymBox2DSensor("LunarLanderContinuous-v2", uuid="gym_box_data"),
]
We define our ActorCriticModel agent using a lightweight implementation with separate MLPs for actors and critic,
MemorylessActorCritic. Since
this is a model for continuous control, note that the superclass of our model is ActorCriticModel[GaussianDistr]
instead of ActorCriticModel[CategoricalDistr], since we'll use a
Gaussian distribution to sample actions.
@classmethod
def create_model(cls, **kwargs) -> nn.Module:
return MemorylessActorCritic(
input_uuid="gym_box_data",
action_space=gym.spaces.Box(
-1.0, 1.0, (2,)
), # 2 actors, each in the range [-1.0, 1.0]
observation_space=SensorSuite(cls.SENSORS).observation_spaces,
action_std=0.5,
)
Task samplers#
We use an available TaskSampler implementation for gym environments that allows to sample
GymTasks:
GymTaskSampler. Even though it is possible to let the task
sampler instantiate the proper sensor for the chosen task name (by passing None), we use the sensors we created
above, which contain a custom identifier for the actual observation space (gym_box_data) also used by the model.
@classmethod
def make_sampler_fn(cls, **kwargs) -> TaskSampler:
return GymTaskSampler(**kwargs)
For convenience, we will use a _get_sampler_args method to generate the task sampler arguments for all three
modes, train, valid, test:
def train_task_sampler_args(
self,
process_ind: int,
total_processes: int,
devices: Optional[List[int]] = None,
seeds: Optional[List[int]] = None,
deterministic_cudnn: bool = False,
) -> Dict[str, Any]:
return self._get_sampler_args(
process_ind=process_ind, mode="train", seeds=seeds
)
def valid_task_sampler_args(
self,
process_ind: int,
total_processes: int,
devices: Optional[List[int]] = None,
seeds: Optional[List[int]] = None,
deterministic_cudnn: bool = False,
) -> Dict[str, Any]:
return self._get_sampler_args(
process_ind=process_ind, mode="valid", seeds=seeds
)
def test_task_sampler_args(
self,
process_ind: int,
total_processes: int,
devices: Optional[List[int]] = None,
seeds: Optional[List[int]] = None,
deterministic_cudnn: bool = False,
) -> Dict[str, Any]:
return self._get_sampler_args(process_ind=process_ind, mode="test", seeds=seeds)
Similarly to what we do in the Minigrid navigation tutorial, the task sampler samples random tasks for ever, while, during testing (or validation), we sample a fixed number of tasks.
def _get_sampler_args(
self, process_ind: int, mode: str, seeds: List[int]
) -> Dict[str, Any]:
"""Generate initialization arguments for train, valid, and test
TaskSamplers.
# Parameters
process_ind : index of the current task sampler
mode: one of `train`, `valid`, or `test`
"""
if mode == "train":
max_tasks = None # infinite training tasks
task_seeds_list = None # no predefined random seeds for training
deterministic_sampling = False # randomly sample tasks in training
else:
max_tasks = 3
# one seed for each task to sample:
# - ensures different seeds for each sampler, and
# - ensures a deterministic set of sampled tasks.
task_seeds_list = list(
range(process_ind * max_tasks, (process_ind + 1) * max_tasks)
)
deterministic_sampling = (
True # deterministically sample task in validation/testing
)
return dict(
gym_env_types=["LunarLanderContinuous-v2"],
sensors=self.SENSORS, # sensors used to return observations to the agent
max_tasks=max_tasks, # see above
task_seeds_list=task_seeds_list, # see above
deterministic_sampling=deterministic_sampling, # see above
seed=seeds[process_ind],
)
Note that we just sample 3 tasks for validation and testing in this case, which suffice to illustrate the model's success.
Machine parameters#
Given the simplicity of the task and model, we can just train the model on the CPU. During training, success should reach 100% in less than 10 minutes, whereas solving the task (evaluation reward > 200) might take about 20 minutes (on a laptop CPU).
We allocate a larger number of samplers for training (8) than for validation or testing (just 1), and we default to
CPU usage by returning an empty list of devices. We also include a video visualizer (AgentViewViz) in test mode.
@classmethod
def machine_params(cls, mode="train", **kwargs) -> Dict[str, Any]:
visualizer = None
if mode == "test":
visualizer = VizSuite(
mode=mode,
video_viz=AgentViewViz(
label="episode_vid",
max_clip_length=400,
vector_task_source=("render", {"mode": "rgb_array"}),
fps=30,
),
)
return {
"nprocesses": 8 if mode == "train" else 1,
"devices": [],
"visualizer": visualizer,
}
Training pipeline#
The last definition is the training pipeline. In this case, we use a PPO stage with linearly decaying learning rate and 80 single-batch update repeats per rollout:
@classmethod
def training_pipeline(cls, **kwargs) -> TrainingPipeline:
ppo_steps = int(1.2e6)
return TrainingPipeline(
named_losses=dict(
ppo_loss=PPO(clip_param=0.2, value_loss_coef=0.5, entropy_coef=0.0,),
), # type:ignore
pipeline_stages=[
PipelineStage(loss_names=["ppo_loss"], max_stage_steps=ppo_steps),
],
optimizer_builder=Builder(cast(optim.Optimizer, optim.Adam), dict(lr=1e-3)),
num_mini_batch=1,
update_repeats=80,
max_grad_norm=100,
num_steps=2000,
gamma=0.99,
use_gae=False,
gae_lambda=0.95,
advance_scene_rollout_period=None,
save_interval=200000,
metric_accumulate_interval=50000,
lr_scheduler_builder=Builder(
LambdaLR, {"lr_lambda": LinearDecay(steps=ppo_steps)}, # type:ignore
),
)
Training and validation#
We have a complete implementation of this experiment's configuration class in projects/tutorials/gym_tutorial.py.
To start training from scratch, we just need to invoke
PYTHONPATH=. python allenact/main.py gym_tutorial -b projects/tutorials -m 8 -o /PATH/TO/gym_output -s 54321 -e
from the allenact root directory. Note that we include -e to enforce deterministic evaluation. Please refer to the
Navigation in MiniGrid tutorial if in doubt of the meaning of the rest of parameters.
If we have Tensorboard installed, we can track progress with
tensorboard --logdir /PATH/TO/gym_output
which will default to the URL http://localhost:6006/.
After 1,200,000 steps, the script will terminate. If everything went well, the valid success rate should quickly
converge to 1 and the mean reward to above 250, while the average episode length should stay below or near 300.
Testing#
The training start date for the experiment, in YYYY-MM-DD_HH-MM-SS format, is used as the name of one of the
subfolders in the path to the checkpoints, saved under the output folder.
In order to evaluate (i.e. test) a collection of checkpoints, we need to pass the --eval flag and specify the
directory containing the checkpoints with the --checkpoint CHECKPOINT_DIR option:
PYTHONPATH=. python allenact/main.py gym_tutorial \
-b projects/tutorials \
-m 1 \
-o /PATH/TO/gym_output \
-s 54321 \
-e \
--eval \
--checkpoint /PATH/TO/gym_output/checkpoints/GymTutorial/YOUR_START_DATE \
--approx_ckpt_step_interval 800000 # Skip some checkpoints
The option --approx_ckpt_step_interval 800000 tells AllenAct that we only want to evaluate checkpoints
which were saved every ~800000 steps, this lets us avoid evaluating every saved checkpoint. If everything went well,
the test success rate should converge to 1, the episode length below or near 300 steps, and the mean reward to above
250. The images tab in tensorboard will contain videos for the sampled test episodes.
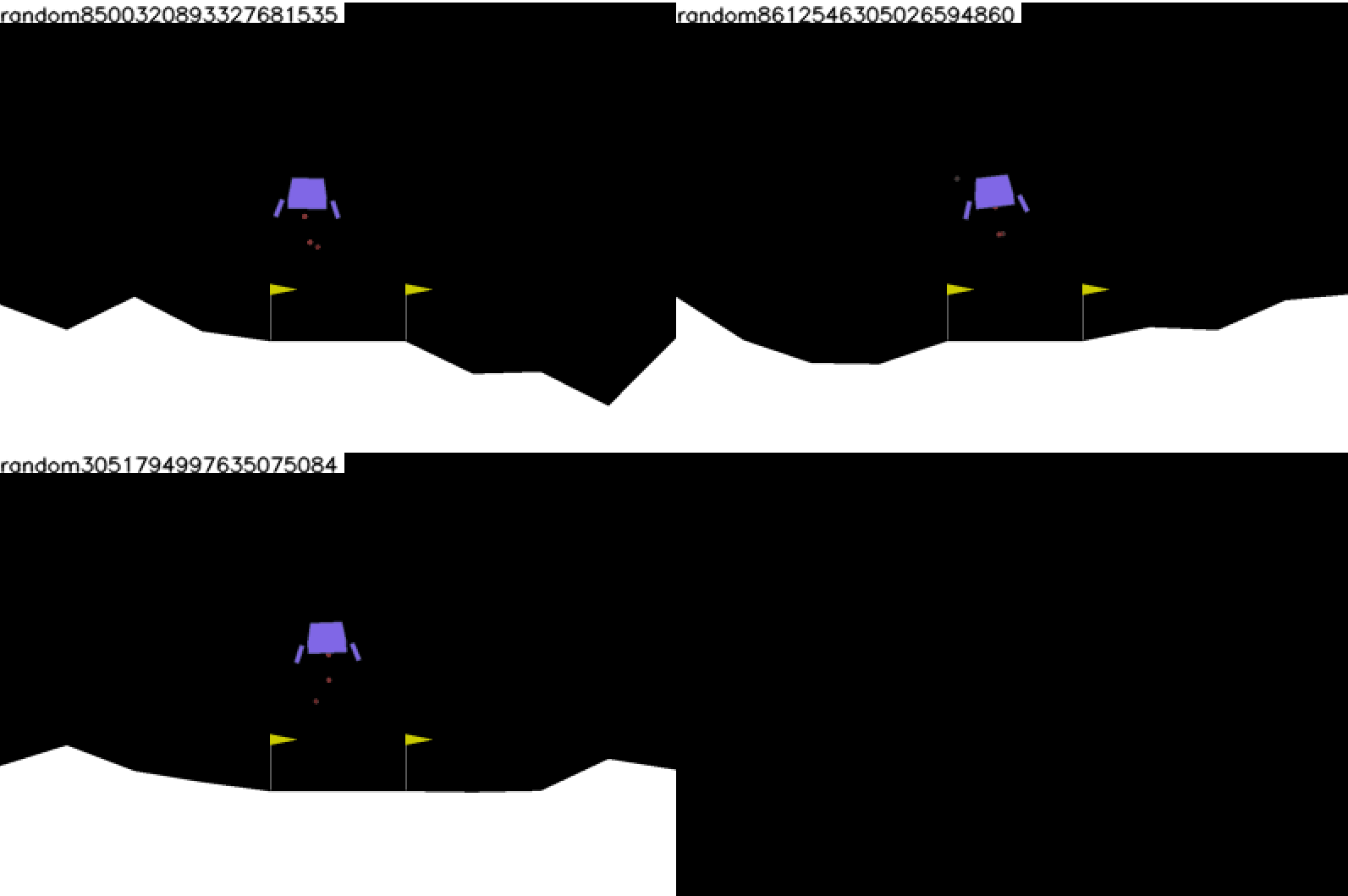 .
.
If the test command fails with pyglet.canvas.xlib.NoSuchDisplayException: Cannot connect to "None", e.g. when running
remotely, try prepending DISPLAY=:0.0 to the command above, assuming you have an xserver running with such display
available:
DISPLAY=:0.0 PYTHONPATH=. python allenact/main.py gym_tutorial \
-b projects/tutorials \
-m 1 \
-o /PATH/TO/gym_output \
-s 54321 \
-e \
--eval \
--checkpoint /PATH/TO/gym_output/checkpoints/GymTutorial/YOUR_START_DATE \
--approx_ckpt_step_interval 800000