Tutorial: Off-policy training.#
Note The provided commands to execute in this tutorial assume you have
installed the full library and the extra_requirements
for the babyai_plugin and minigrid_plugin. The latter can be installed with:
pip install -r allenact_plugins/babyai_plugin/extra_requirements.txt; pip install -r allenact_plugins/minigrid_plugin/extra_requirements.txt
In this tutorial we'll learn how to train an agent from an external dataset by imitating expert actions via
Behavior Cloning. We'll use a BabyAI agent to solve
GoToLocal tasks on MiniGrid; see the
projects/babyai_baselines/experiments/go_to_local directory for more details.
This tutorial assumes AllenAct's abstractions are known.
The task#
In a GoToLocal task, the agent immersed in a grid world has to navigate to a specific object in the presence of
multiple distractors, requiring the agent to understand go to instructions like "go to the red ball". For further
details, please consult the original paper.
Getting the dataset#
We will use a large dataset (more than 4 GB) including expert demonstrations for GoToLocal tasks. To download
the data we'll run
PYTHONPATH=. python allenact_plugins/babyai_plugin/scripts/download_babyai_expert_demos.py GoToLocal
from the project's root directory, which will download BabyAI-GoToLocal-v0.pkl and BabyAI-GoToLocal-v0_valid.pkl to
the allenact_plugins/babyai_plugin/data/demos directory.
We will also generate small versions of the datasets, which will be useful if running on CPU, by calling
PYTHONPATH=. python allenact_plugins/babyai_plugin/scripts/truncate_expert_demos.py
from the project's root directory, which will generate BabyAI-GoToLocal-v0-small.pkl under the same
allenact_plugins/babyai_plugin/data/demos directory.
Data iterator#
In order to train with an off-policy dataset, we need to define a data Iterator.
The Data Iterator merges the functionality of the Dataset and Dataloader in PyTorch,
in that it defines the way to both sample data from the dataset and convert them into batches to be
used for training.
An
example of a Data Iterator for BabyAI expert demos might look as follows:
class ExpertTrajectoryIterator(Iterator):
def __init__(
self,
data: List[Tuple[str, bytes, List[int], MiniGridEnv.Actions]],
nrollouts: int,
rollout_len: int,
instr_len: Optional[int],
restrict_max_steps_in_dataset: Optional[int] = None,
num_data_length_clusters: int = 8,
current_worker: Optional[int] = None,
num_workers: Optional[int] = None,
):
...
def add_data_to_rollout_queue(self, q: queue.Queue, sampler: int) -> bool:
...
def get_data_for_rollout_ind(self, rollout_ind: int) -> Dict[str, np.ndarray]:
...
def __next__(self) -> Dict[str, torch.Tensor]:
...
A complete example can be found in ExpertTrajectoryIterator.
Loss function#
Off-policy losses must implement the AbstractOffPolicyLoss interface. In this case, we minimize the cross-entropy between the actor's policy and the expert action:
class MiniGridOffPolicyExpertCELoss(AbstractOffPolicyLoss[ActorCriticModel]):
def __init__(self, total_episodes_in_epoch: Optional[int] = None):
super().__init__()
self.total_episodes_in_epoch = total_episodes_in_epoch
def loss( # type:ignore
self,
model: ActorCriticModel,
batch: ObservationType,
memory: Memory,
*args,
**kwargs
) -> Tuple[torch.FloatTensor, Dict[str, float], Memory, int]:
rollout_len, nrollouts = cast(torch.Tensor, batch["minigrid_ego_image"]).shape[
:2
]
# Initialize Memory if empty
if len(memory) == 0:
spec = model.recurrent_memory_specification
for key in spec:
dims_template, dtype = spec[key]
# get sampler_dim and all_dims from dims_template (and nrollouts)
dim_names = [d[0] for d in dims_template]
sampler_dim = dim_names.index("sampler")
all_dims = [d[1] for d in dims_template]
all_dims[sampler_dim] = nrollouts
memory.check_append(
key=key,
tensor=torch.zeros(
*all_dims,
dtype=dtype,
device=cast(torch.Tensor, batch["minigrid_ego_image"]).device
),
sampler_dim=sampler_dim,
)
# Forward data (through the actor and critic)
ac_out, memory = model.forward(
observations=batch,
memory=memory,
prev_actions=None, # type:ignore
masks=cast(torch.FloatTensor, batch["masks"]),
)
# Compute the loss from the actor's output and expert action
expert_ce_loss = -ac_out.distributions.log_prob(batch["expert_action"]).mean()
info = {"expert_ce": expert_ce_loss.item()}
if self.total_episodes_in_epoch is not None:
if "completed_episode_count" not in memory:
memory["completed_episode_count"] = 0
memory["completed_episode_count"] += (
int(np.prod(batch["masks"].shape)) # type: ignore
- batch["masks"].sum().item() # type: ignore
)
info["epoch_progress"] = (
memory["completed_episode_count"] / self.total_episodes_in_epoch
)
return expert_ce_loss, info, memory, rollout_len * nrollouts
A complete example can be found in MiniGridOffPolicyExpertCELoss. Note that in this case we train the entire actor, but it would also be possible to forward data through a different subgraph of the ActorCriticModel.
Experiment configuration#
For the experiment configuration, we'll build on top of an existing
base BabyAI GoToLocal Experiment Config.
The complete ExperimentConfig file for off-policy training is
here, but let's
focus on the most relevant aspect to enable this type of training:
providing an OffPolicyPipelineComponent object as input to a
PipelineStage when instantiating the TrainingPipeline in the training_pipeline method.
class BCOffPolicyBabyAIGoToLocalExperimentConfig(BaseBabyAIGoToLocalExperimentConfig):
"""BC Off-policy imitation."""
DATASET: Optional[List[Tuple[str, bytes, List[int], MiniGridEnv.Actions]]] = None
GPU_ID = 0 if torch.cuda.is_available() else None
@classmethod
def tag(cls):
return "BabyAIGoToLocalBCOffPolicy"
@classmethod
def METRIC_ACCUMULATE_INTERVAL(cls):
# See BaseBabyAIGoToLocalExperimentConfig for how this is used.
return 1
@classmethod
def training_pipeline(cls, **kwargs):
total_train_steps = cls.TOTAL_IL_TRAIN_STEPS
ppo_info = cls.rl_loss_default("ppo", steps=-1)
num_mini_batch = ppo_info["num_mini_batch"]
update_repeats = ppo_info["update_repeats"]
# fmt: off
return cls._training_pipeline(
named_losses={
"offpolicy_expert_ce_loss": MiniGridOffPolicyExpertCELoss(
total_episodes_in_epoch=int(1e6)
),
},
pipeline_stages=[
# Single stage, only with off-policy training
PipelineStage(
loss_names=[], # no on-policy losses
max_stage_steps=total_train_steps, # keep sampling episodes in the stage
# Enable off-policy training:
offpolicy_component=OffPolicyPipelineComponent(
# Pass a method to instantiate data iterators
data_iterator_builder=lambda **extra_kwargs: create_minigrid_offpolicy_data_iterator(
path=os.path.join(
BABYAI_EXPERT_TRAJECTORIES_DIR,
"BabyAI-GoToLocal-v0{}.pkl".format(
"" if torch.cuda.is_available() else "-small"
),
),
nrollouts=cls.NUM_TRAIN_SAMPLERS // num_mini_batch, # per trainer batch size
rollout_len=cls.ROLLOUT_STEPS,
instr_len=cls.INSTR_LEN,
**extra_kwargs,
),
loss_names=["offpolicy_expert_ce_loss"], # off-policy losses
updates=num_mini_batch * update_repeats, # number of batches per rollout
),
),
],
# As we don't have any on-policy losses, we set the next
# two values to zero to ensure we don't attempt to
# compute gradients for on-policy rollouts:
num_mini_batch=0,
update_repeats=0,
total_train_steps=total_train_steps,
)
# fmt: on
You'll have noted that it is possible to combine on-policy and off-policy training in the same stage, even though here we apply pure off-policy training.
Training#
We recommend using a machine with a CUDA-capable GPU for this experiment. In order to start training, we just need to invoke
PYTHONPATH=. python allenact/main.py -b projects/tutorials minigrid_offpolicy_tutorial -m 8 -o <OUTPUT_PATH>
Note that with the -m 8 option we limit to 8 the number of on-policy task sampling processes used between off-policy
updates.
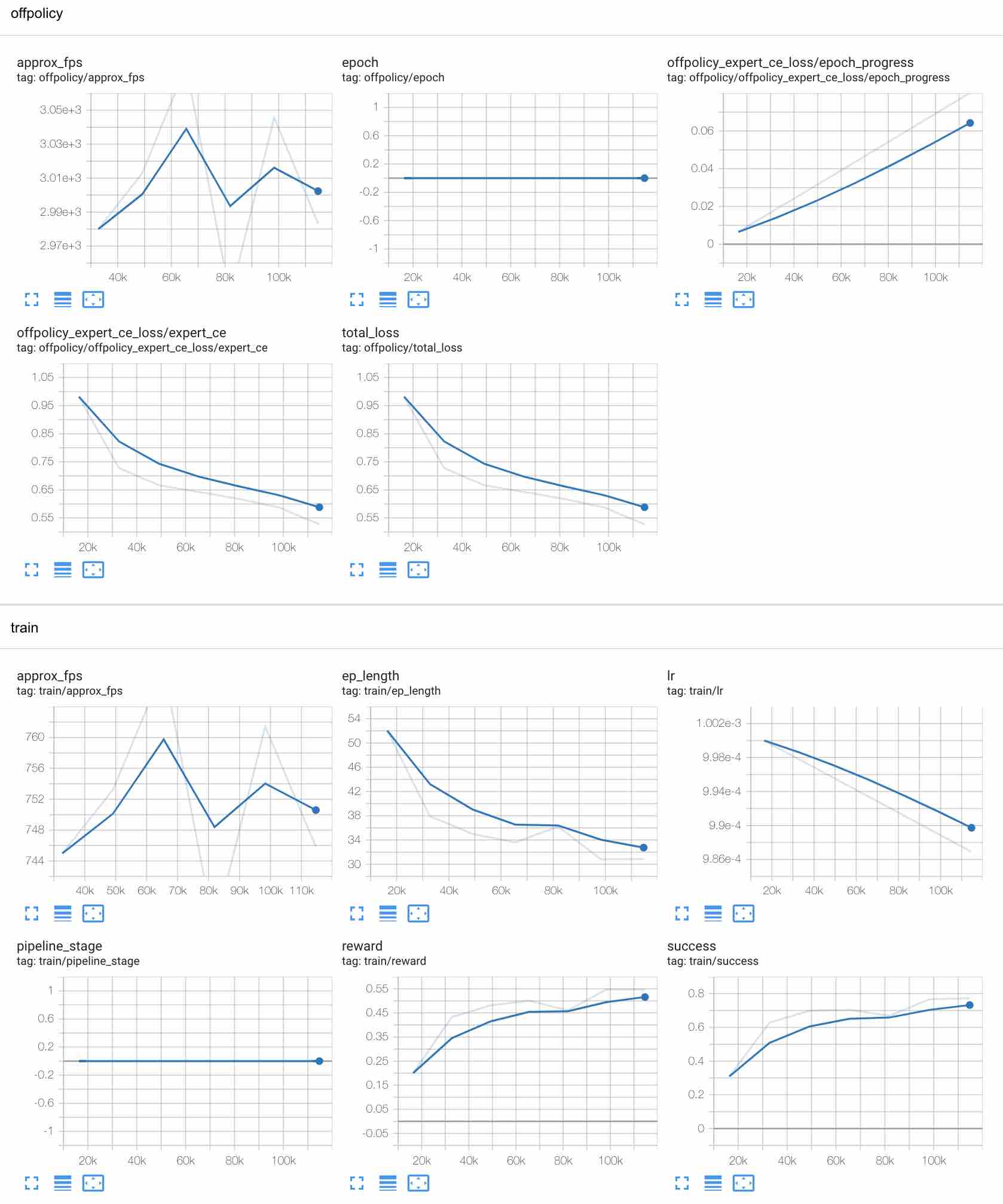
If everything goes well, the training success should quickly reach values around 0.7-0.8 on GPU and converge to values close to 1 if given sufficient time to train.
If running tensorboard, you'll notice a separate group of scalars named offpolicy with losses, approximate frame rate
and other tracked values in addition to the standard train used for on-policy training.
A view of the training progress about 5 minutes after starting on a CUDA-capable GPU should look similar to